Media Summary: While large-scale unsupervised language models (LMs) learn broad world knowledge and some reasoning skills, achieving ... Don't like the Sound Effect?:* *LLM Training Playlist:* ... Hii, Today we are reviewing the paper called RLHF - Reinforcement Learning From Human Feedback. It is one of the pioneering ...
Direct Preference Optimization Dpo Math Insight Explained - Detailed Analysis & Overview
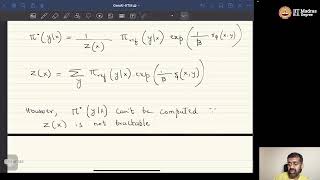
While large-scale unsupervised language models (LMs) learn broad world knowledge and some reasoning skills, achieving ... Don't like the Sound Effect?:* *LLM Training Playlist:* ... Hii, Today we are reviewing the paper called RLHF - Reinforcement Learning From Human Feedback. It is one of the pioneering ... AIResearch The video lecture discusses and explains the derivation of ... Join Discord to tell us your ideas about the video: Title: SimPO: Simple Support BrainOmega ☕ Buy Me a Coffee: Stripe: ...













![[2024 Best AI Paper] SimPO: Simple Preference Optimization with a Reference-Free Reward](https://i.ytimg.com/vi/aqXgqbIZ5z0/mqdefault.jpg)




