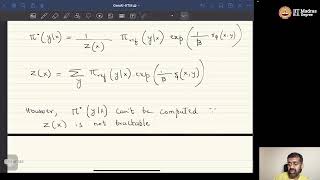
Media Summary: Don't like the Sound Effect?:* *LLM Training Playlist:* ... Hii, Today we are reviewing the paper called RLHF - Reinforcement Learning From Human Feedback. It is one of the pioneering ... AIResearch The video lecture discusses and explains the derivation of ...
Direct Preference Optimization Dpo Explained Bradley Terry Model Log Probabilities Math - Detailed Analysis & Overview
Don't like the Sound Effect?:* *LLM Training Playlist:* ... Hii, Today we are reviewing the paper called RLHF - Reinforcement Learning From Human Feedback. It is one of the pioneering ... AIResearch The video lecture discusses and explains the derivation of ...