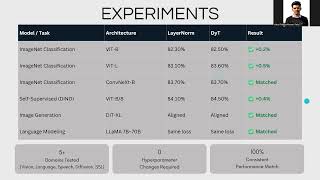
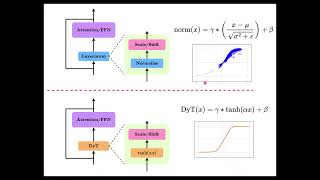
Media Summary: [CVPR 2026] Official video of Dynamic erf (Derf). In this AI Research Roundup episode, Alex discusses the paper: ' This video presents a summary of the CVPR
Stronger Normalization Free Transformers Dec 2025 - Detailed Analysis & Overview
[CVPR 2026] Official video of Dynamic erf (Derf). In this AI Research Roundup episode, Alex discusses the paper: ' This video presents a summary of the CVPR As a regular normal SWE, want to share several key topics to better understand Transformers Without Normalization: The Dynamic Tanh Paradigm Adapting a model to an individual writing style: LoRA, prompting, and the limits of automatic evaluation. CSCI E-104 Advanced ...
Today, we're exploring the groundbreaking paper ' For more information about Stanford's graduate programs, visit: October 31, Check out Sebastian Raschka's book Build a Large Language Model (From Scratch) In this ...