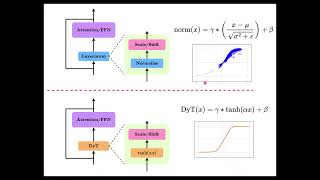
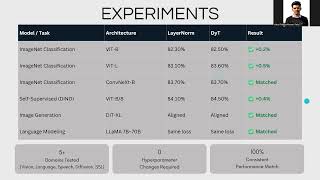
Media Summary: Transformers Without Normalization: The Dynamic Tanh Paradigm I recently came across this paper titled, " This video presents a summary of the CVPR 2025 paper “
Transformers Without Normalization The Dynamic Tanh Paradigm - Detailed Analysis & Overview
Transformers Without Normalization: The Dynamic Tanh Paradigm I recently came across this paper titled, " This video presents a summary of the CVPR 2025 paper “ LayerNorm is outdated? Let's find it out together. As a regular normal SWE, want to share several key topics to better understand We just wrapped up our second Genloop Research Jam where we explored Meta's
Reference: Paper: Code and website: MoBoard (Video Maker): ...