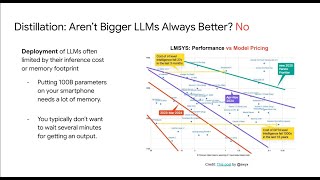
Media Summary: Jason Fries, a research scientist at Snorkel AI and Stanford University, discussed the challenges of deploying Large Language Models like GPT-4, DeepSeek, and Google Gemini or Flash comes with a major drawback—they are massive AI models are growing massive—but what if we could shrink them to fit your phone without losing performance? Let's dive
Distilling Knowledge Into Tiny Llms - Detailed Analysis & Overview
Jason Fries, a research scientist at Snorkel AI and Stanford University, discussed the challenges of deploying Large Language Models like GPT-4, DeepSeek, and Google Gemini or Flash comes with a major drawback—they are massive AI models are growing massive—but what if we could shrink them to fit your phone without losing performance? Let's dive This video lesson explores the power of Large Language Model Welcome! I'm Aman, a Data Scientist & AI Mentor. Foundation model performance at a fraction of the cost- model
Compressing Llama 3.1: 8 B→4 B with Pruning and






![How to Distill LLM? LLM Distilling [Explained] Step-by-Step using Python Hugging Face AutoTrain](https://i.ytimg.com/vi/tpMOF1cT4Fc/mqdefault.jpg)












