Media Summary: What if you could skip redundant LLM calls — and make your AI app faster, cheaper, and smarter? In this video, ... Stop overpaying for your LLM API calls! If you are building AI applications, you've likely noticed that costs scale quickly. Your AI app is as fast as its database. But repeated queries in reasoning loops can turn milliseconds into seconds. The Remote ...
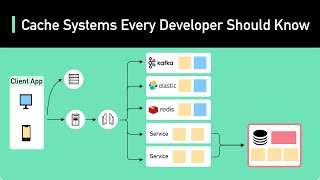
Caching For Agentic Java Systems Internal Distributed And Semantic - Detailed Analysis & Overview
What if you could skip redundant LLM calls — and make your AI app faster, cheaper, and smarter? In this video, ... Stop overpaying for your LLM API calls! If you are building AI applications, you've likely noticed that costs scale quickly. Your AI app is as fast as its database. But repeated queries in reasoning loops can turn milliseconds into seconds. The Remote ... Don't leave your software engineering career to chance. Make sure you're interview-ready with Exponent's Your LLM agents are slow and burning cash because they repeat the same expensive calls over and over. In this video, I show ... In this video, we dive into LMCache, an open-source KV
Checkout the Spring Boot + DevOps Course: ... Nitin Kanukolanu, Applied AI Engineer at Redis, focused on Ever wondered how large-scale applications like Amazon, Netflix, and Facebook handle millions of requests without breaking ... One common concern of developers building AI applications is how fast answers from LLMs will be served to their end users, ... Ready to become a certified watsonx Generative AI Engineer? Register now and use code IBMTechYT20 for 20% off of your exam ...