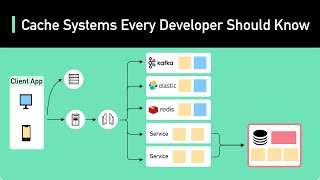
Media Summary: What if you could skip redundant LLM calls — and make your AI app faster, cheaper, and smarter? In this video, ... A cache is a high-speed memory that efficiently stores frequently accessed data. Ready to become a certified watsonx Generative AI Engineer? Register now and use code IBMTechYT20 for 20% off of your exam ...
What Is A Semantic Cache - Detailed Analysis & Overview
What if you could skip redundant LLM calls — and make your AI app faster, cheaper, and smarter? In this video, ... A cache is a high-speed memory that efficiently stores frequently accessed data. Ready to become a certified watsonx Generative AI Engineer? Register now and use code IBMTechYT20 for 20% off of your exam ... One common concern of developers building AI applications is how fast answers from LLMs will be served to their end users, ... Get a Free System Design PDF with 158 pages by subscribing to our weekly newsletter.: Animation ... This is how to enhance the performance of intelligent applications by implementing
Your LLM agents are slow and burning cash because they repeat the same expensive calls over and over. In this video, I show ... Stop overpaying for your LLM API calls! If you are building AI applications, you've likely noticed that costs scale quickly. Are your AI agents slow, expensive, or repetitive? Large Language Models (LLMs) often waste significant time and money ... Ready to become a certified Qiskit Developer? Register now and use code IBMTechYT20 for 20% off of your exam ... Nitin Kanukolanu, Applied AI Engineer at Redis, focused on Your LLM app is costing you a fortune because of one simple mistake. It's not about what users ask, but what they mean.
Tyler Hutcherson, Applied AI Engineering Lead at Redis, explores how This video breaks down production-grade RAG system design — including document ingestion, chunking, embeddings, vector search ... Learn how Amazon ElastiCache for Valkey 8.2 brings Vector Search to your in-memory data layer. See how Multi-agent AI systems now orchestrate complex workflows requiring frequent foundation model calls. In this session, learn how ...