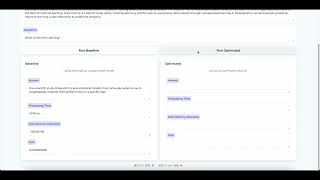
Media Summary: See the detailed reference architecture → Learn how to use JAX, Google Kubernetes Engine (GKE) and ... Many techniques have been proposed to both accelerate and compress trained Deep Neural Networks (DNNs) for deployment on ... Are your margins being crushed by the "per-token tax"? While
Ace3 Ai Inference Performance Acceleration Comparison - Detailed Analysis & Overview
See the detailed reference architecture → Learn how to use JAX, Google Kubernetes Engine (GKE) and ... Many techniques have been proposed to both accelerate and compress trained Deep Neural Networks (DNNs) for deployment on ... Are your margins being crushed by the "per-token tax"? While Try FreshBooks free, for 30 days, no credit card required at While working on the smart home ... Learn how to use JAX, Google Kubernetes Engine (GKE) and NVIDIA Triton Join Microsoft's Anthony Shaw and NVIDIA's Steven McCullough for a deep dive into













![Accelerating AI Model Performance [APAC]](https://i.ytimg.com/vi/XHuASkNXLho/mqdefault.jpg)

