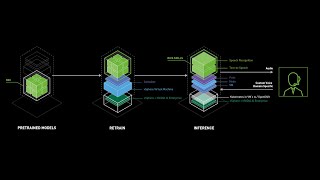
Media Summary: In this episode, we sit down with Solution Architect Robert Alvarez to discuss the technology behind Pure Key-Value Accelerator ... Don't miss out! Join us at our next Flagship Conference: KubeCon + CloudNativeCon Europe in London from April 1 - 4, 2025. This YouTube video delves into the growing popularity of generative
Accelerating Ai Inference Workloads - Detailed Analysis & Overview
In this episode, we sit down with Solution Architect Robert Alvarez to discuss the technology behind Pure Key-Value Accelerator ... Don't miss out! Join us at our next Flagship Conference: KubeCon + CloudNativeCon Europe in London from April 1 - 4, 2025. This YouTube video delves into the growing popularity of generative Don't miss out! Join us at our next Flagship Conference: KubeCon + CloudNativeCon North America in Salt Lake City from ... Are your margins being crushed by the "per-token tax"? While Talk : Introductions and Meetup Updates by Chris Fregly and Antje Barth Talk : Optimizing