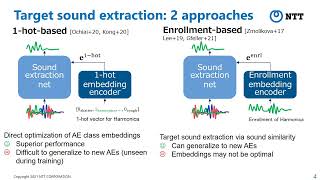
Media Summary: Want to play with the technology yourself? Explore our interactive demo → Learn more about the ... This short video introduces the SepFormer (Separation Transformer) for SepFormer is a fully attention based masking architecture for source
One Shot Learning For Speech Separation - Detailed Analysis & Overview
Want to play with the technology yourself? Explore our interactive demo → Learn more about the ... This short video introduces the SepFormer (Separation Transformer) for SepFormer is a fully attention based masking architecture for source Large Language Models are a very powerful tool. And to elicit desired information from LLMs, effective prompts are a must. Title: Dual-Path Filter Network: Speaker-Aware Modeling for I show how to separate out the voices of two speakers from
Ruohan Gao & Kristen Grauman (UT Austin & Facebook AI Research) Papaer: Project page: ... Dr. Jonathan Le Roux of MERL demos their system for Title: Speaker Verification-Based Evaluation of First try at solving the "cocktail party" problem















![[DLHLP 2020] Speech Separation (1/2) - Deep Clustering, PIT](https://i.ytimg.com/vi/tovg5ZxNgIo/mqdefault.jpg)