Media Summary: Welcome! I'm Aman, a Data Scientist & AI Mentor. In today's session, we break down Here I try to explain the basic idea behind Authors: Zhenzhu Zheng (University of Delaware)*; Xi Peng (University of Delaware) Description: We present Self-Guidance, ...
Knowledge Distillation In Deep Neural Network - Detailed Analysis & Overview
Welcome! I'm Aman, a Data Scientist & AI Mentor. In today's session, we break down Here I try to explain the basic idea behind Authors: Zhenzhu Zheng (University of Delaware)*; Xi Peng (University of Delaware) Description: We present Self-Guidance, ... Authors: Pham, Cuong; Hoang, Tuan NA; Do, Thanh-Toan* Description: "ScaleDowStudy Group: Optimisation Techniques: In this video, i try to explain how distilBERT model was trained to create a smaller faster version of the famous BERT model using ...
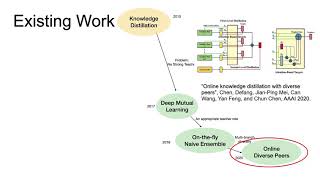
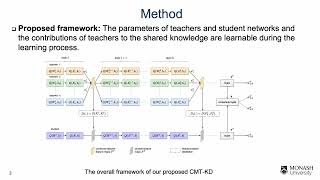
tl;dr: This lecture covers various effective model compression techniques such as quantization, pruning, and This is the first and foundational paper that started the research area of 230623 Towards Understanding Ensemble, Knowledge Distillation and Self-Distillation in Deep Learning