Media Summary: Try Voice Writer - speak your thoughts and let AI handle the grammar: The KV Most devs are using LLMs daily but don't have a clue about some of the fundamentals. Understanding tokens is crucial because ... Ready to become a certified watsonx Generative AI Engineer? Register now and use code IBMTechYT20 for 20% off of your exam ...
Key Value Cache In Large Language Models Explained - Detailed Analysis & Overview
Try Voice Writer - speak your thoughts and let AI handle the grammar: The KV Most devs are using LLMs daily but don't have a clue about some of the fundamentals. Understanding tokens is crucial because ... Ready to become a certified watsonx Generative AI Engineer? Register now and use code IBMTechYT20 for 20% off of your exam ... In this video, we unravel the importance and The research introduces Q-Filters, a novel, training-free method for compressing the Don't like the Sound Effect?:* *LLM Training Playlist:* ...
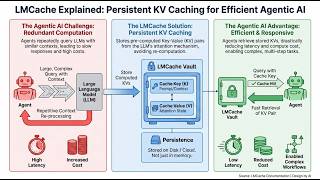
Thanks to KiwiCo for sponsoring today's video! Go to and use code WELCHLABS for 50% off ... In this video, I explore the mechanics of KV In this AI Research Roundup episode, Alex discusses the paper: 'HySparse: A Hybrid Sparse Attention Architecture with Oracle ... In this video, we dive into LMCache, an open-source KV












![How DeepSeek Rewrote the Transformer [MLA]](https://i.ytimg.com/vi/0VLAoVGf_74/mqdefault.jpg)