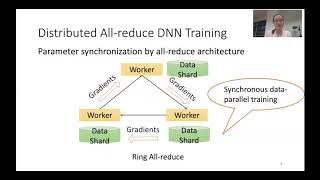
Media Summary: On Hopsworks, learn how to: 1. train a TensorFlow model using many GPUs using Hopsworks 2. how to use CollectiveAllReduce ... A complete tutorial on how to train a model on multiple GPUs or multiple servers. I first describe the difference between Data ... Google Cloud Developer Advocate Nikita Namjoshi introduces how
Distributed Training All Reduce Colllective Operations - Detailed Analysis & Overview
On Hopsworks, learn how to: 1. train a TensorFlow model using many GPUs using Hopsworks 2. how to use CollectiveAllReduce ... A complete tutorial on how to train a model on multiple GPUs or multiple servers. I first describe the difference between Data ... Google Cloud Developer Advocate Nikita Namjoshi introduces how This video describes the data flow in Harp (map In this video, we break down NCCL (NVIDIA Yixin Bao, Yanghua Peng, Yangrui Chen, Chuan Wu. "Preemptive
All to All Broadcast and Reduction Operation To access the translated content: 1. The translated content of this course is available in regional languages. For details please ...